Índice
Tablas de correlación y tablas de contingencia
- Una variable n-dimensional recogerá la información de n características de cada ítem o individuo de forma simultánea.
- En este tema nos centraremos en el estudio de las variables bidimensionales, que recogerán por tanto, dos características de cada ítem o individuo incluido en la muestra de forma simultánea.
- De este modo, para organizar la información no será suficiente con las distribuciones de frecuencias y tendremos que utilizar tablas de correlaciones o tablas de contigencia.
Las tablas de correlación o tablas de contingencia presentan la siguiente estructura:
| X\Y | 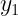 |
… | 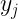 |
… |  |
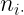 |
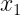 |
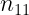 |
… |  |
… | 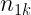 |
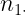 |
 |
|
|
|
… | |
|
 |
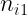 |
… | 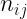 |
… | 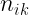 |
|
|
|
|
|
… | |
|
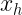 |
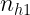 |
… | 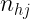 |
… |  |
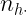 |
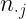 |
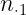 |
… | |
… |  |
N |
Estas tablas contienen en la primera fila y la primera columna los valores de cada una de las variables en estudio. En el interior incluyen las frecuencias con las que se repite cada par de valores. Por ejemplo, 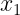

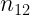
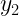
Las tablas de correlación también pueden tener la siguiente estructura:
 |
 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Las denominaremos tablas de correlación cuando incluyan variables numéricas y tabla de contingencia cuando incluyan atributos.
Ejemplo 1.- Supongamos que una aseguradora pretenden analizar la posible relación entre el número de accidentes de coche que tiene una persona a lo largo de su vida y el número de punto que refleja su carnet de conducir. Tomando datos de sus clientes podría obtener la siguiente muestra:
| Y | 0 | 1 | 2 | 3 | |
|
| X | ||||||
| 8 | 0 | 2 | 4 | 7 | 13 | |
| 12 | 2 | 3 | 4 | 1 | 10 | |
| 15 | 9 | 8 | 3 | 1 | 21 | |
|
11 | 13 | 11 | 9 | 44 | |
Distribuciones marginales
Las distribuciones marginales muestran los datos aislados de cada una de las variables incluidas en la tabla de correlación.
Para construirlas tomaremos como siempre en la primera columna los distintos valores que presenta la variable y obtendremos las frecuencias del siguiente modo:
- Para el valor i-ésimo de la variable X, la frecuencia marginal será:
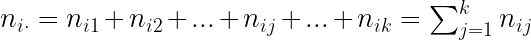
- Análogamente, la frecuencia marginal del valor j-ésimo de Y será:
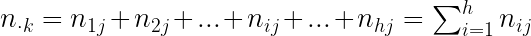
Las distribuciones marginales presentarán la siguiente estructura:
| X | |
|
|
 |
|
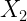 |
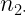 |
|
|
|
|
|
|
 |
|
| N | |
| Y | |
|
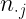 |
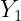 |
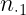 |
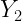 |
 |
|
|
|
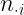 |
|
|
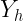 |
 |
| N | |
Aunque habitualmente se presentan en la misma tabla de correlación como una fila o columna final. A partir de estas distribuciones podemos calcular cualquiera de las medidas unidimensionales que hemos aprendido hasta el momento.
Distribuciones condicionadas
Las distribuciones condicionadas muestran la distribución de una de las variables condicionada a que la otra variable tome un valor concreto.
Por ejemplo, nos puede interesar la distribución de la variable X condicionada a que Y tome el valor 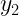
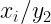 |
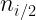 |
|
|
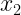 |
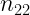 |
|
|
|
 |
|
|
|
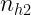 |
 |
En general, podemos expresar las distribuciones condicionadas de x e y mediante:
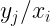 |
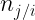 |
|
|
|
|
|
|
|
|
|
|
|
|
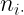 |
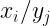 |
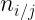 |
|
|
|
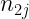 |
|
|
|
|
|
|
|
|
|
Podemos definir además las frecuencias relativas de la distribución condicionada de X a algún valor de Y, o de la distribución condicionada de Y a algún valor de X serán, respectivamente:


Estructuras de dependencia
Definición.- Dependencia funcional
Diremos que dos variables X e Y presentan una relación de dependencia funcional cuando existe una función tal que Y = f(x), es decir una función que transforma de forma perfecta los valores de X en los valores de Y.
Definición.- Dependencia estadística
Existe dependencia estadística entre X e Y cuando ambas variables están relacionadas, pero no existe una función matemática mediante la cual podamos obtener los valores de Y a partir de los valores de X.
Hablaremos entonces del grado de dependencia estadística que presentan las variables, ya que estás relaciones estadísticas pueden ser más o menos fuertes.
La dependencia estadística entre variables se denomina correlación y entre atributos contingencia.
Definición.- Independencia
Diremos que X e Y son independientes cuando exista ningún tipo de relación entre ellas.
Independencia estadística
Cuando dos variables son independientes estadísticamente su frecuencia relativa conjunta será igual al producto de las frecuencias relativas marginales:
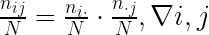
En esta situación, las frecuencias relativas condicionadas serán iguales a las relativas marginales, es decir,

Covarianza
Para analizar el grado de relación que presentan dos variables X e Y utilizaremos la covarianza.
Definición.- Covarianza
La covarianza es una medida del grado de variación conjunta entre dos variables estadísticas, respecto a sus medias. Se obtiene mediante la siguiente fórmula:
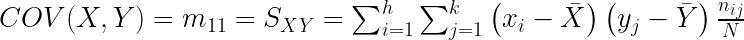
Cuando X e Y son independientes la covarianza entre ellas es 0. Pero el reciproco no es cierto.
Si las variables presentan una relación positiva (cuando una crece la otra también crece) la covarianza será positiva. Si la relación entre las variables es negativa, la covarianza también lo será.
Momentos bidimensionales
La covarianza es un momento bidimensional. Definiremos en general los momentos bidimensionales de forma análoga a la definición de momentos unidimensionales. Distinguiremos por tanto también entre momentos respecto al origen y momentos respecto a la media:
Momentos respecto al origen:
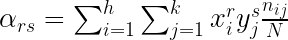
De los momentos bidimensionales respecto al origen destacaremos:

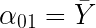
Momentos respecto a las medias:
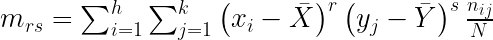
De los momentos bidimensionales respecto a las medias destacaremos:
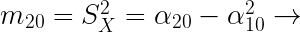

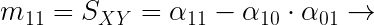
Como siempre, los momentos con respecto a la media se pueden calcular a partir de momentos respecto al origen. Encontramos así un método alternativo par el calculo de la covarianza.
Transformaciones lineales
Recordemos el comportamiento de las principales medidas estadísticas ante transformaciones lineales de las variable.
Consideraremos para ello las variables X e Y para las que conocemos las medias ( 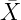

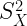

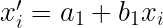
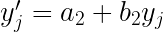
Veamos como se comportarán las diferentes medidas:
| Las medias se transformarán del mismo modo que los datos | 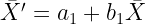
|
| Las varianzas no se ven afectadas por cambios respecto al origen y los cambios de escala les afectan al cuadrado. | 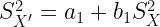
|
| La covarianza solo se verá afectada por cambios de escala. | 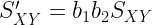 |

Ejemplo de cálculo de la covarianza
Para el ejemplo considerado la covarianza será:
| Y | 0 | 1 | 2 | 3 | |
|
| X | ||||||
| 8 | 0 | 2 | 4 | 7 | 13 | |
| 12 | 2 | 3 | 4 | 1 | 10 | |
| 15 | 9 | 8 | 3 | 1 | 21 | |
|
11 | 13 | 11 | 9 | 44 | |
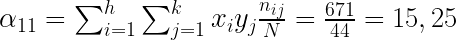
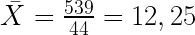
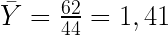
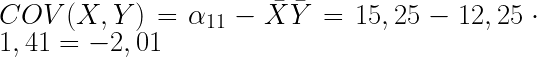
Vemos que existe relación entre las variables y es negativa. Cuantos más punto tiene una persona menos accidentes ha tenido.