Índice
Una de las hipótesis en las que se basa el modelo de regresión lineal básico es que las variables explicativas que incluye el modelo deben ser independientes entre sí. En la práctica esta independencia es difícil de encontrar, pero sí es importante analizar el grado de relación lineal que presentan las variables explicativas. En este sentido el modelo puede presentar 3 situaciones diferentes:
- Ortogonalidad.
- Multicolinealidad perfecta.
- Multicolinealidad imperfecta.
Ortogonalidad
Diremos que un modelo presenta Ortogonalidad cuando la correlación que presentan las variables explicativas que incluye entre sí es nula.
La ortogonalidad implica por tanto que no existen relaciones lineales entre los regresores del modelo. Esto no supone el incumplimiento de ninguna de las hipótesis de nuestro modelo. Al contrario, sabemos que una de las hipótesis básicas del modelo es que las variables explicativas sean independientes entre sí. En la práctica sin embargo, encontrar variables complemente independientes es difícil, con lo que será difícil que nuestro modelo presente ortogonalidad.
Multicolinealidad perfecta
La multicolinealidad perfecta en un modelo de regresión lineal indica las existencia de relaciones lineales exactas entre un conjunto de regresores del modelo.
Si por ejemplo el modelo:

diremos que existe multicolinealidad perfecta si encontramos variables que tengan las siguientes relaciones entre sí:
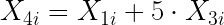
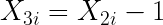
Se observa por tanto, que la multicolinealidad perfecta puede afectar a dos o más variables explicativas. En cualquier caso, la multicolinealidad perfecta implica que es posible obtener los valores exactos de alguna variable a partir de los valores de otra u otras, o dicho de otro modo, que una variable es proporcional a otra o puede obtenerse como combinación lineal de los valores de otras.
Esta relación perfecta entre variables explicativas sí supone el incumplimiento una de las hipótesis básicas del modelo, la que nos habla, como ya adelantábamos de la independencia entre variables explicativas. Esta hipótesis se puede relajar y existen modelo válidos cuyos regresores no son completamente independientes, cosa que ya hemos visto que es difícil de encontrar en la práctica. Sin embargo, necesitamos que las variables explicativas no presenten relaciones exactas entre sí para poder calcular los estimadores de los parámetros del modelo, ya que como sabemos se calculan mediante la expresión 
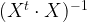
que ante filas o columnas iguales o proporcionales tendrá determinante 0. Ante la imposibilidad de calcular los estimadores de los parámetros, Eviews muestra el siguiente mensaje de error:

Como la multicolinealidad perfecta surge cuando una variable explicativa es porporcional a otra o puede obtenerse como combinación lineal de otras, desde el punto de vista estadístico podemos decir que las variables implicadas contienen exactamente la misma información, por lo que la forma más sencilla de resolver el problema es simplemente eliminar una de las variables que lo generan.
Otra posible solución sería ampliar la muestra, ya que la multicolinealidad es un problema muestral.
A igual la ortogonalidad, en la práctica los modelos no suelen presentar multicolinealidad perfecta, ya que las relaciones entre las distintas variables económicas no suele ser exacta. Sin embargo en ocasiones nos encontramos con este problema cuando generamos variables artificiales como pueden ser variables dummies. En estas situaciones hay que tener cuidado de generarlas adecuadamente para que no resulten presentar combinaciones lineales perfectas.
Multicolinealidad Imperfecta
Decimos que un modelo de regresión múltiple presenta multicolinealidad imperfecta cuando existen relaciones lineales fuertes entre algunas de sus variables explicativas, que no llegan a ser perfectas.
Ejemplo.- Si tratamos de explicar el gasto en telefonía que tienen las familias y utilizamos como variables explicativas:
- El número de miembros de la unidad familiar
- El gasto en vivienda
- La renta
- El número de dispositivos con conexión a internet
Observando las variables explicativas seleccionadas sin duda encontraremos que es de esperar que presenten altas correlaciones entre sí, pues el número de dispositivos con conexión a internet, por ejemplo, sin duda está relacionado con el número de miembros de la unidad familiar. También podemos esperar que la renta se relacione con el gasto en vivienda y con el número de dispositivos con conexión.
Es muy común encontrar multicolinealidad imperfecta o simplemente multicolinealidad en los modelos econométricos. Se incumpliría con ello la hipótesis básica de independencia entre las variables explicativas, pero ya al enunciarla decíamos que era difícil de cumplir.
Consecuencias de la multicolinealidad
Aún en presencia de multicolinealidad, los estimadores de mínimos cuadrados ordinarios siguen siendo los mejores estimadores que podemos obtener, ya que siguen cumpliendo propiedades importantes como la insesgadez.
Pero cuando un modelo presenta problemas de multicolinealidad, encontraremos en el los siguientes problemas:
- Los errores estándar de estimación son anormalmente grandes, o más elevados de lo que deberían. Como sabemos, los errores estándar de estimación son las desviaciones típicas de los estimadores, y cuando son elevadas, los estimadores son menos fiables, ya que pueden fluctuar más dependiendo de la muestra seleccionada.
- Se habla también de inestabilidad de los estimadores de los parámetros, que está muy relacionada con lo anterior. Esta inestabilidad viene como consecuencia del aumento en las varianzas de los estimadores y se traduce en grandes diferencias de las estimaciones ante pequeñas variaciones muestrales.
- Dificultad en la interpretación de los coeficientes estimados. Los coeficientes de regresión (
) miden el cambio que se produce en la variable dependiente (y) ante variaciones de una unidad en la variable independiente (
), asumiendo que el resto de las variables explicativas permanecen constantes.
Cuando existe multicolinealidad imperfecta es imposible suponer que el resto de las variables permanecen constantes cuando una cambia, ya que si están altamente relacionadas, cambios en una implicarán cambios en el resto. Por este motivo los parámetros pierden significado.
Ejemplo de detección de la multicolinealidad
Plantearemos un modelo que el que se pretende explicar el ahorro neto de las familias de una determinada población (Ahorro_familiar) a partir de las siguiente variables:
Renta_familiar: Renta neta disponible por familia.
Impuestos: Impuestos directos pagados por las familias.
Tamaño_familiar: Número medio de personas que conviven en el entorno familiar.
Para ello se dispone de una muestra con los datos totales para toda la población en el periodo desde 1980 hasta 2014.
Si generamos en Eviews el modelo que explica el ahorro neto familiar en función de la renta neta disponible de las familias, de los impuestos directos y del tamaño familiar obtenemos la siguiente salida:

No hay contrastes específicos de uso generalizado para el estudio de la multicolinealidad. Lo más habitual es estudiarla por 2 vías:
- Observanado las correlaciones de las variables explicativas, contenidas en su matriz de correlaciones y el determinante de la matriz de correlaciones.
- Analizanado los contrastes de significación individual y conjunta de los regresores.
Matriz de correlaciones de las variable explicativas
En la matriz de correlaciones de las variables explicativas podremos observar el coeficiente de correlación lineal, como medida del
grado de relación lineal existente entre cada par de variable exógenas incluidas en el modelo.
Sabemos que cuando el valor absoluto de un coeficiente de correlación lineal es elevado (próximo a ±1), existe una relación lineal fuerte entre el par de variables analizado. La existencia de relaciones lineales fuertes entre las variables explicativas es un indicio de la existencia de problemas de multicolinealidad en el modelo.
Para obtener la matriz de correlacioens en Eviews se deben abrir las variables explicativas como grupo. En las vistas del grupo podremos seleccionar:
view -> covariance analysis
Por defecto tiene marcada una opción para mostrar la matriz de varianzas-covarianzas. Debemos deseleccionarla y seleccionar la opción “correlations”. En nuestro ejemplo la matriz de correlaciones es:

A la vista de la matriz de correlaciones podemos observar que todas las variables explicativas están fuertemente relacionadas entre si, presentado coeficientes de correlación lineal superiores en todo caso a 0,7 en valor absoluto. Esto es un indicio claro de presencia de multicolinealidad en el modelo.
Determinante de la matriz de correlaciones de las variable explicativas
Incluso si los coeficientes de correlación lineal no fueran tan elevados, podría ocurrir que existiese una fuerte multicolinealidad, como consecuencia de la relación entre más de 2 variables. Recordemos que el coeficiente de correlación lineal solo será capaz de detectar relaciones entre dos variables. En este sentido, debemos observar también el determinante de la matriz de correlaciones para detectarla la presencia de multicolinealidad derivada de relaciones que involucren a más de dos variables explicativas. El determinante de la matriz de correlaciones nos dará una medida de la relación de las variables en su conjunto.
Un determinante muy bajo (cercano a cero) indicará altas intercorrelaciones entre las variables. Si el determinante llegase a cero indicaría la existencia de relaciones lineales perfectas entre las variables explicativas y por tanto presencia de multicolinealidad perfecta en el modelo. Debemos comprobar por tanto, si el determinante la matriz de correlaciones de los regresores es cercano a cero. Si lo es, tendremos indicios de problemas de multicolinealidad en el modelo.
Para calcular el determinante de la matriz de correlaciones debemos seguir los siguiente pasos:
- Abrir las variables explicativas como grupo y guardar el grupo. Recordemos que para guardar el grupo bastará con darle un nombre, por ejemplo “grupo_explicativas”.
- Guardar como matriz, la matriz de correlaciones del grupo creado. Para ello debemos escribir en la ventana de comandos:
Sym Matriz_correlaciones=@cor(grupo_explicativas)
- Calcular el determinante de la matriz generada, escribiendo en la ventana de comandos:
Scalar determinante=@det(Matriz_correlaciones)

Como resultado nos aparecerán los objetos “grupo_explicativas”, “matriz_correlaciones” y “determinante” en el worfile, tal y como podemos observar en la imagen.
En este caso, el determinante de nuestra matriz de correlaciones es igual a 0,002761. Este valor es muy próximo a cero, lo que indica de nuevo la presencia de multicolinealidad en el modelo.
Significatividad individual y conjunta de las variables explicativas
Ya hemos visto que en presencia de multicolinealidad imperfecta los errores estándar de estimación de los parámetros se hacen anormalmente grandes. En esta situación los contrastes de significatividad individual tienden a fallar, aceptando como variables no significativas a variables con capacidad explicativa sobre la variable dependiente.
Esto sucede porque el estadístico de contraste se calcula dividiendo el valor estimado del parámetro en cuestión entre su varianza y si la varianza es grande el resultado de esta división se acercará a cero, convirtiéndose así en un valor razonable para la distribución t-student que seguiría si la variable no es significativa.
Para detectar esta situación tenemos dos opciones:
- Observar si las variables que aparecen como no significativas en el modelo están altamente correlacionadas con la variable dependiente.
- Observar si las variables que aparecen como no significativas en el modelo generan por si solas modelos significativos.
En nuestro modelo, si tenemos en cuenta el contraste de significatividad individual diremos que las variables tamaño e impuestos no son significativas. Incluso en el caso de la variable renta familiar no podemos rechazar la hipótesis nula de no significatividad individual. Estamos entonces ante un modelo que explica un 94,69% de la variabilidad de la variable dependiente pero no incluye ninguna variable significativa a nivel de significación 0,05.
Además, observando las correlaciones con la variable dependiente veremos que todas las variables están muy relacionadas con esta:

Estamos claramente ante un caso de multicolinealidad, en el que los contrastes de significatividad individual están fallando debido a los altos valores de las varianzas de los estimadores de los parámetros.
Por otro lado, si plantemos modelo que expliquen el ahorro familiar con cada una de estas variables de forma individual encontraremos modelos significativos en ambos casos.


Vemos que ambos modelos explican suficientemente la variabilidad de la variable ahorro, por lo que no podemos considerar a ninguna de estas variables como no significativa.
Medidas de corrección de la multicolinealidad
Como la multicolinealidad es un problema muestral, podríamos resolverla simplemente ampliando la muestra. No obstante, si teníamos acceso a más información deberíamos haberla usado desde el principio. Además, cuando dos variables están verdaderamente relacionadas entre sí, ampliando la muestra no eliminamos estas relaciones.
Otra solución más extendida en uso para eliminar la multicolinealidad imperfecta de un modelo es eliminar alguna de las variables implicadas en el problema, es decir, si por ejemplo dos variables son casi proporcionales, simplemente eliminando una del modelo resolveremos el problema a cambio de eliminar la información proporcionada por esta variable. En este caso caeríamos en un problema de omisión de una variable relevante. Pero este problema no sería muy relevante ya que, si dos variables tienen una correlación cercada a 1, prácticamente la totalidad de la información contenida en una, estará también en la otra. En este sentido, si estamos buscando el mejor modelo para la predicción, la eliminación de variables puede ser una buena solución.
Otra solución práctica puede ser la transformación de las variables explicativas del modelo. Se puede recurrir a transformar la variables de algún modo, para intentar que estas transformaciones mantengan la esencia del comportamiento de las variables y disminuyan a la vez el grado de correlación entre los regresores.
Las transformaciones más habituales son el cálculo de los incrementos de la variables (si se trata de una serie temporal) o relativizarlas con respecto a una variable común (por ejemplo ponerlas en término per cápita).
En nuestro ejemplo podemos volver a estimar el modelo con las variables expresadas en incrementos o diferencias de orden 1. Para ello usaremos la función D(variable).
Ejercicio.- Estimar el nuevo modelo y estudiar su multicolinealidad.
Si los fines que se persiguen con la construcción del modelo son predictivos, el problema de la multicolinealidad no es tan relevante, ya que no afecta a la capacidad explicativa conjunta de la variables y ni, por tanto, a su capacidad predictiva.