Índice
- Análisis descriptivo de las variables
- Análisis de las relaciones con la variable dependiente
- Estimación del modelo
- Interpretación de los parámetros
- Contraste de normalidad
- Error estándar
- Contraste de significatividad individual
- Coeficiente de determinación
- Coeficiente de determinación corregido
- Otros estadísticos de interés
- Estadístico de Durbin-Watson
- Criterios de información de Akaike y Schwarz
- Contraste de significatividad global
- Algunas herramientas Eviews sobre la estimación
Ejemplo.-
Supongamos que un investigador pretende encontrar los factores que afectan al grado de estrés de los trabajadores. Esta será por tanto nuestra variable dependiente (Y) y lo mediremos mediante la tensión nerviosa.
Inicialmente nos plantearemos como variables explicativas el tamaño de la empresa en la que trabaja cada trabajador (tamanno), la antigüedad en el puesto actual, medida en años (antiguedad), el salario anual bruto (en miles) percibido por el trabajador (salario) y la edad del trabajador (edad).
Se dispone para el estudio de una muestra de 100 observaciones.
Análisis descriptivo de las variables
Eviews calcula los principales estadísticos descriptivos de las variables del grupo a través de su menú:
View -> Descriptive Stats -> Common Sample

Análisis de las relaciones con la variable dependiente
Antes de especificar el modelo debemos analizar las relaciones existentes entre las variables explicativas y la variable explicada, para confirmar si existe entre ellas una relación línea.
Para obtener los gráficos de dispersión en Eviews debemos agrupar las variables en un grupo, colocando la primera a la variable dependiente. Desde el grupo elegiremos la opción:
Views -> Graph
Que nos llevará al siguiente cuadro de diálogo:

Selecionando el gráfico de dispersión (Scatter plot) y la opción “Multiple graphs –First vs. All”, obtendremos los gráficos de dispersión de cada una de las variables explicativas frente a la variable dependiente.
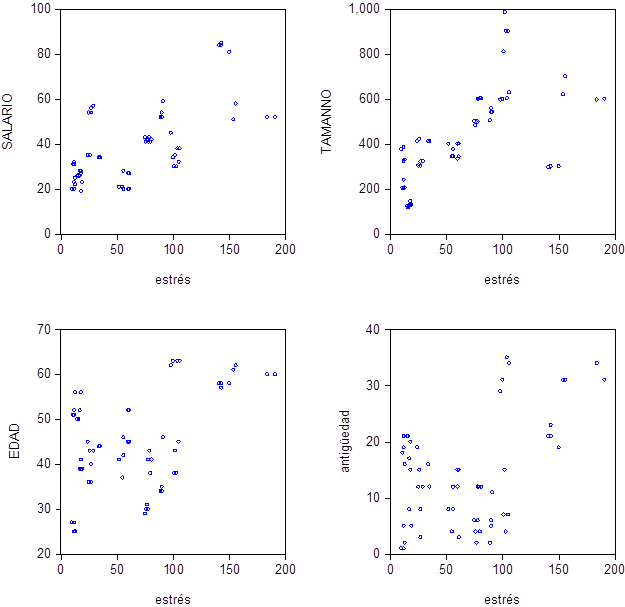
En nuestro caso tendremos:

La matriz de correlaciones muestra el coeficiente de correlación entre cada par de variables.
Nos interesa que las variables independientes estén muy relacionadas con la variable dependiente, para que puedan explicar adecuadamente su variabilidad.
Por otro lado nos interesa que las variables independientes no presenten fuertes correlaciones entre sí. Si así fuera tendríamos un problema de multicolinealidad en el modelo.
En este caso observando la matriz de correlaciones vemos que las variables más correlacionadas con el estrés son el tamaño de la empresa y el salario anual, aunque también existe cierta correlación entre el estrés y los años de trabajo en el puesto actual y la edad.
Por otro lado comprobamos que, como ya se observaba en los gráficos de dispersión, la correlación entre el estrés y todas las variables explicativas es positiva.
Entre las variables explicativas las correlaciones no son muy altas, salvo en el caso de las variables antigüedad en el puesto actual y edad, como era de esperar.
Estimación del modelo
Plantearemos el modelo de regresión lineal:

Podemos estimar el modelo en Eviews de 3 formas distintas:
1.En los procedimientos del objeto grupo (Procs), seleccionando:
Procs -> Make Equation
2. Abriendo las variables (series) que intervienen como un objeto ecuación. En este caso, desde la ventana del Workfile, debemos seleccionar las series que intervienen en el modelo usando la tecla CTRL y con el botón derecho del ratón, hacemos doble clic en la selección y después Open Equation.
3. Seleccionando en el menú principal:
Quick -> Estimate Equation
Los tres caminos conducen al cuadro de diálogo de la especificación del modelo, que es el siguiente:

La ecuación del modelo de regresión, puede expresarse de varias formas:
1.Como lista de variables, incluyendo primero la variable dependiente:
Ejemplo.- estres salario tamanno edad antiguedad c
2.Como ecuación, nombrando a los coeficientes con C(1), C(2),… tal y como aparece en el título de la ventana para la especificación del modelo en el cuadro de diálogo.
Ejemplo.- estres=c(1)+c(2)*salario +(3)*tamanno+c(4)*edad+c(5)*antiguedad
Por defecto, si hemos accedido al cuadro de diálogo seleccionando previamente las variables, EViews utiliza la primera opción manteniendo el orden de la selección de las variables en el grupo e introduciendo siempre el término independiente al final.
Tras introducir la ecuación, podemos seleccionar el método de estimación.
Por defecto, EViews utiliza mínimos cuadrados ordinarios, LS – Least Squares (NLS and ARMA)
También podemos seleccionar la muestra con la que queremos que trabaje, indicando la primera observación que debe utilizar y la última. Por defecto aparecerá indicado que utilice todas las observaciones de la muestra.
El resultado de la estimación es el siguiente:

En la parte superior aparece el nombre de la variable dependiente, el método de estimación empleado, la fecha y la hora de realización, el periodo muestral y el número de observaciones que abarca el mismo.
En segundo lugar encontramos la estimación de los coeficientes asociados a cada una de las variables explicativas junto con el error estándar de estimación, el contraste de significatividad individual para cada variable y la probabilidad de error de tipo I (p-valor) del mismo.
En la zona inferior hay un bloque de estadísticos de bondad de ajuste, que nos permiten evaluar parcialmente la regresión realizada.
La columna coefficient recoge el valor de los estimadores de los parámetros asociados a cada una de las variables explicativas, obtenidos en el caso de la estimación de mínimos cuadrados ordinarios, a partir de la expresión matricial:

Si se cumplen las hipótesis clásicas del modelo de regresión múltiple señaladas anteriormente, éstos estimadores son lineales, insesgados y óptimos (ELIO).
Estos estimadores miden la magnitud de influencia de cada variable sobre la variable dependiente, entendiendo que las demás permanecen constantes.
Interpretación de los parámetros
Podemos entender cada uno de estos coeficientes como la variación que experimenta la variable endógena ante un cambio unitario de la variable explicativa correspondiente, suponiendo que el resto de las variables permanecen constantes.
En nuestro ejemplo podemos decir que:
– Cuando la empresa en la que trabaja un individuo incluye un trabajador más, permaneciendo el resto de las variables constantes, el grado de estrés del individuo (su presión arterial) aumenta en 0,1286 unidades.
– Por cada año adicional del trabajador su presión arterial aumenta en 1,4693 y cada 1000€ más de salario anual bruto hacen subir la presión arterial del individuo en 1,3327.
– La antigüedad en el puesto también hace subir el estrés del trabajador, en caso cada año aumenta la presión arterial 0,0034 siempre teniendo en cuenta que el resto de variables permanece constante.
En esta situación la ecuación de nuestro modelo es:

Con esta ecuación podríamos predecir la presión arterial de un individuo, considerándola como la medida de su estrés, si tuviésemos la información de las 4 variables explicativas que incluye el modelo, asumiendo el modelo como válido.
El resto de la información que aparece en la pantalla del modelo nos ayudará a medir la bondad del ajuste.
Contraste de normalidad
Antes de comenzar a analizar los contrastes de hipótesis asociados al modelo de regresión lineal múltiple es importante comprobar si se cumple la hipótesis de normalidad del error (H9)
Recordemos que la hipótesis 9 decía: “El término error es un término completamente aleatorio que sigue una distribución normal, de esperanza 0 (![E[\epsilon_i]=0](https://s0.wp.com/latex.php?latex=E%5B%5Cepsilon_i%5D%3D0&bg=ffffff&fg=000&s=1&c=20201002)
Los contrastes de hipótesis asociados al modelo de regresión múltiple son todos contrastes paramétricos, por lo que no serán aplicables si no se cumple esta hipótesis de normalidad del error.
Para comprobar la normalidad del error, podemos aplicar el contraste Jarque-Bera a los residuos del modelo. Podemos hacerlo en Eviews de varias formas:
1. Abriendo la serie residuos y accediendo
View -> Descriptives statistics and test -> Histogram and stats
En este caso, si estamos trabajando con varios modelos a la vez debemos tener cuidado de que los residuos guardados en resid sean los que realmente nos interesan. Podemos comprobarlo observando la fecha y hora en que fueron calculados
2. Desde el objeto ecuación accediendo a:
View -> Residual diagnosis – Histogram and normality test
En ambos casos obtendremos:

Donde aparece el contraste de normalidad Jarque-Bera.
Recordemos que el test Jarque-Bera contrasta la hipótesis nula de normalidad.
En este caso, con un p-valor de 0,8768 debemos decir que, a nivel de significación 0,05 no tenemos evidencias suficientes para rechazar que la muestra provenga de una distribución normal.
Error estándar
Volviendo a la estimación del modelo, junto a la columna de coeficientes tenemos la columna STD Error que muestra el error estándar de la estimación.
El error estándar es la desviación típica de los estimadores de los parámetros del modelo y mide la precisión con la que dichos estimadores estiman los parámetros del modelo.
Nos indican por tanto, el grado de confianza que podemos tener en la estimación.
Sabemos que, siempre que se cumplan las hipótesis básicas del modelo, los estimadores de mínimos cuadrados ordinarios son eficientes, es decir, que tienen la menor varianza (y en consecuencia desviación típica) que pueden tener.
Contraste de significatividad individual
La siguiente columna incluye el t-statistic, el estadístico del contraste de significatividad individual.
Este test contrasta la hipótesis nula de que la variable considerada no es individualmente significativa para explicar el comportamiento de la variable dependiente, es decir:

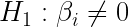
El estadístico de contraste de este test es:
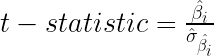
Sabemos que bajo 
La región crítica será por tanto:
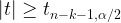
La siguiente columna, probability nos indica la probabilidad de cometer el error de rechazar la hipótesis nula siendo cierta (error de tipo I), en el contraste de significatividad individual. No da por tanto el p-valor.
Este p-valor está considerando que bajo la hipótesis nula, el estadístico de contraste sigue una distribución t de student con n-k-1 grados de libertad, siendo k el número de variables represoras del modelo.
En el modelo planteado debemos rechazar la hipótesis nula de no significatividad de las variables en el caso de la edad, el tamaño de la empresa y el salario, concluyendo por tanto que estas variables sí son significativas a la hora de explicar el estrés de los trabajadores.
Para la variable antigüedad, por el contrario, a nivel de significación 0,05 no podemos rechazar la hipótesis nula de no significatividad, con lo que debemos considerar que no es significativa para explicar el estrés de los trabajadores.
Coeficiente de determinación
En la tabla inferior aparece el coeficiente de determinación (R-Squared (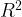

Nos explica por tanto el porcentaje de variación de la variable dependiente que conseguimos explicar con el modelo.
En nuestro ejemplo vemos que la capacidad explicativa de las variables es elevada, pues explican el 78,76% de la variabilidad de la variable endógena.
Coeficiente de determinación corregido
El coeficiente de determinación corregido, Adjusted R-squared (
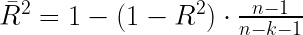
Este coeficiente permite comparar la capacidad explicativa de modelos referidos a una misma muestra de la misma variable dependiente con distinto número de variables independientes.
En nuestro caso obtenemos un valor de 0,7721. Si lo comparamos con el valor que obtenemos al estimar un modelo con las mismas variables explicativas menos la antigüedad (0,7762), podemos concluir que este último modelo es mejor que el anterior por ser el R cuadrado ajustado mayor.
Si comparásemos directamente el coeficiente de determinación observaríamos que este siempre sube al incluir nuevas variables, aunque no sean significativas.
Otros estadísticos de interés
El dato S.E. of regression (Error estándar de la regresión), es la estimación de la desviación típica del error, de modo que su cuadrado es la varianza del error. Se obtiene mediante la siguiente expresión:
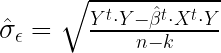
Sum squared resid es la suma de los residuos al cuadrado (SCE) o variabilidad no explicada por el modelo (VNE). Se obtiene mediante:
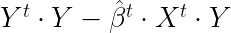
Log likelihood nos da el valor máximo de la función de verosimilitud. Este valor máximo se dará para los estimadores de los parámetros, ya que sabemos que los estimadores de mínimos cuadrados ordinarios coinciden con los de máxima verosimilitud, que serán los que maximizan la probabilidad de la muestra, o los más verosímiles dada la muestra disponible.
Estadístico de Durbin-Watson
El estadístico de Durbin-Watson nos permite contrastar la hipótesis de incorrelación entre las perturbaciones aleatorias del modelo frente a la presencia de autocorrelación. Se calcula a partir de la siguiente expresión:

Lo estudiaremos en profundidad cuando analicemos los problemas de autocorrelación en el modelo.
En la siguiente columna tenemos primero algunas características básicas de la variable dependiente como su media (Mean dependent var) y su cuasi desviación típica muestral (S.D. dependent var).
Criterios de información de Akaike y Schwarz
Los criterios de información de Akaike y Schwarz proporcionan un método para la elección del mejor modelo a partir de una muestra dada.
Ambos son medidas de la perdida de información que tenemos al modelizar la variable con el modelo planteado.
Se calculan a partir de las siguientes expresiones:
AIC = -2*(L/N)+2*((k+1)/N)
BIC = -2*(L/N) + (k+1)*Ln(N)/N
Siendo L el valor máximo de la función de verosimilitud, k el número de variables explicativas del modelo y N el tamaño muestral.
En nuestro ejemplo tienen valores:
AIC=-2*(-271,0014/60) + 2*(4+1)/60 = 9,20
BIC = -2*(-271,0014/60) + (4+1)*Ln(60)/60 = 9,37
Contraste de significatividad global
El contraste de significatividad global (F-statistic), contrasta las siguientes hipotesis:


Se utiliza por tanto, para contrastar si todos los parámetros asociados a las variables explicativas del modelo son iguales a cero. La alternativa indicaría que, al menos uno es distinto de cero.
Es un contraste para corroborar si el modelo es válido o debemos realizar una nueva especificación.
El estadístico del contraste es:

Bajo la hipótesis nula, el estadístico F sigue una distribución F-Snedecor (n-1;n-k-1), de modo que la región crítica será: F>F-Snedecor (n-1;n-k);α
Este contraste puede considerarse como un modo de determinar si el coeficiente de determinación del modelo es suficientemente grande como para considerar que la capacidad explicativa del modelo es adecuada.
Algunas herramientas Eviews sobre la estimación
En Eviews, todos los estadísticos calculados para la estimación se almacenan temporalmente en @funciones y se pueden extraer en forma de objetos diferentes como escalares, vectores o matrices.
A partir de la información de la estimación podemos generar escalares (números) o matrices. Para generar valores número se utiliza la palabra reservada “Scalar” y para generar matrices “matrix”.
Las siguientes funciones nos permitirán guardar un escalar:
@coefs(i) -> Contiene la estimación del parámetro βi.
@stderrs(i) -> Contiene el error estándar o desviación típica estimada de la estimación de βi.
@tstats(i) -> Contiene el estadístico t para el parámetro βi.
@r2 -> Contiene el R2 del modelo.
@rbar2 -> Contiene el del modelo.
@SE -> Contiene la desviación típica del error.
@meandep -> Contiene la media de la variable dependiente.
@sddep -> Contiene la deviación típica de la variable dependiente.
@f -> Contiene el valor del estadístico F.
Además @cov(i,j) proporciona el elemento i,j de la matriz de varianzas y covarianzas estimada de los estimadores de los parámetros del modelo y @ncoef recoge el número de parámetros incluidos en la ecuación del modelo.
Las siguientes funciones nos permitirán guardar matrices:
@coefs -> Contiene las estimaciones de los parámetros βi.
@stderrs -> Contiene los errores estándar de las estimaciones de los βi o desviaciones típicas estimadas para los estimadores de los parámetros.
@tstats -> Contiene la matriz con los estadísticos t para cada parámetro βi.
Ejemplos.-
Para generar un objeto escalar que guarde el valor del coeficiente de determinación haremos:
Scalar coefdet=@r2
Para generar una matriz que guarde las estimaciones de los parámetros del modelo haremos:
Matrix coeficientes=@coefs
Si queremos guardar resultados de una ecuación anteriormente calculada y guardada debemos hacer:
Scalar coefdet =NombreEcuacion.@r2
View -> Representations
Muestra la especificación del modelo y la ecuación del modelo estimado:

View -> Estimation Output
Presenta la salida de la estimación que ya hemos comentado.
View -> Covariance Matrix
Muestra la matriz de varianzas y covarianzas estimada de los estimadores de los coeficientes del modelo, obtenida a partir de:
![VAR[\hat{\beta}]=\hat {\sigma}_{\epsilon}^2 \cdot \left( X^t \cdot X \right)^{-1}](https://s0.wp.com/latex.php?latex=VAR%5B%5Chat%7B%5Cbeta%7D%5D%3D%5Chat+%7B%5Csigma%7D_%7B%5Cepsilon%7D%5E2+%5Ccdot+%5Cleft%28+X%5Et+%5Ccdot+X+%5Cright%29%5E%7B-1%7D+&bg=ffffff&fg=000&s=3&c=20201002)

View -> Actual, Fitted, Residual
Estas opciones permiten obtener gráficos y tablas con los valores observados (Actual) y estimados (Fitted) de la variable dependiente y con los residuos (residual).
-> Actual, Fitted, Residual Table

-> Actual, Fitted, Residual Graph

-> Residual Graph

-> Standarized Residual Graph

- Procs -> Make Residual Series
Se utiliza para almacenar los residuos de un modelo en una nueva serie.
- Procs -> Forecast
Se utiliza para almacenar los valores estimados de la variable endógena en una nueva serie.
- Procs -> Make Regressor Group
Se utiliza para crear un objeto grupo con las variables que intervienen en el modelo.
- Procs -> Specify/Estimate
Nos vuelve a situar en el cuadro de dialogo que permite introducir el modelo a estimar.
View -> Representations
Muestra la especificación del modelo y la ecuación del modelo estimado:
View -> Estimation Output
Presenta la salida de la estimación que ya hemos comentado.
View -> Covariance Matrix
Muestra la matriz de varianzas y covarianzas estimada de los estimadores de los coeficientes del modelo, obtenida a partir de:
View -> Actual, Fitted, Residual
Estas opciones permiten obtener gráficos y tablas con los valores observados (Actual) y estimados (Fitted) de la variable dependiente y con los residuos (residual).
-> Actual, Fitted, Residual Table
-> Actual, Fitted, Residual Graph
-> Residual Graph
-> Standarized Residual Graph
- Procs -> Make Residual Series
Se utiliza para almacenar los residuos de un modelo en una nueva serie.
- Procs -> Forecast
Se utiliza para almacenar los valores estimados de la variable endógena en una nueva serie.
- Procs -> Make Regressor Group
Se utiliza para crear un objeto grupo con las variables que intervienen en el modelo.
- Procs -> Specify/Estimate
Nos vuelve a situar en el cuadro de dialogo que permite introducir el modelo a estimar.