Índice
Cómo incluir variables cualitativas en el modelo de regresión lineal
En ocasiones hay variables cualitativas relevantes para explicar el comportamiento de la variable endógena que nos interesa. Estas variables cualitativas reflejan características, atributos o decisiones de los items que sean de nuestro interés: individuos, países, empresas…
Algunos ejemplos de variables que pueden resultar de interés son:
- Para individuos: Sexo, raza, religión, nivel de estudios, ocupación, lugar de residencia, preferencias políticas…
- Para empresas: Formato jurídico, sector, presencia en Internet…
- Para países: Nivel de desarrollo, continente, presencia en alguna institución internacional…
Otras veces disponemos de variables explicativas numéricas categorizadas en intervalos. Este formato se suele utilizar para obtener información delicada en la que los individuos pueden tener reparos a la hora de responder como por ejemplo cuando preguntamos por la edad o la renta.
Para incluir variables cualitativas en un modelo econométrico es necesario construir variables ficticias, binarias o dicotómicas más conocidas por variables dummies. Las variables ficticias o dummies toman dos valores arbitrarios, 1 si la observación presenta la característica en cuestión y el 0 en caso contrario.
Si queremos incluir en un modelo econométrico la presencia en Internet de una empresa podríamos definirla del siguiente modo:

Como vemos, si la variable de interés tiene 2 categorías bastará con crear una variable ficticia para codificarla. Pero si la variable cualitativa que queremos incorporar al modelo tiene más de 2 categorías, tendremos que crear tantas variables ficticias dicotómicas como categorías tenga la variable menos una.
La elección del valor asociado a cada categoría es arbitraria y solo implica que la característica asociada al valor 0 actúa como categoría base o de referencia. En el caso anterior podríamos haber definido:
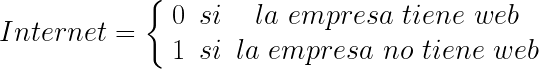
Si incluimos en un modelo tantas variables dummies como categorías tiene la variable cualitativa a incluir caeremos en la denominada trampa de las variables ficticias. Cuando esto sucede, las variables dummies construyen una combinación lineal exacta, por lo que no se podrán obtener los estimadores de mínimos cuadrados ordinarios ya que 
Podemos generar variables dummies en Eviews y Gretl añadiendo una nueva variable que construiremos a partir de operadores lógicos (Ver guía de Eviews y/o Gretl.
Ejemplo completo de análisis de variables cualitativas
Los ficheros hoteles.wf1 contienen datos para una muestra de hoteles de la costa española para los que se conocen las siguientes variables:
- Precio: Precio medio diario en temporada alta de la habitación.
- Dis: Distancia a la playa más cercana en metros.
- Hab: Número de habitaciones del hotel.
- Est: Categoría del hotel medida con el número de estrellas.
- Pcn: Toma valor 1 si el hotel tiene piscina y 0 en otro caso.
En este ejemplo tenemos 2 variables cualitativas Est y Pcn. La variable Pcn solo tiene dos categorías y ya está codificada como variable dummy:

La variable Est sin embargo toma valores entre 2 y 5 (ya que la muestra no incluye hoteles de 1 estrella), por lo que debe ser codificada mediante variables dummy.
Para codificar la variable Est mediante variables dummies, tendremos que crear 3 variables, ya que tenemos 4 categorías.

Para generar estas variables dummies en Eviews debemos usar la opción Genr de la barra de herramientas del Workfile e incluir: Est3=Est=3; Est4=Est=4 y Est5=Est=5 respectivamente.
Cuando se incluyen variables cualitativas en un modelo econométrico se entiende que la variable dependiente presenta un comportamiento diferente para las distintas categorías de dicha variable. En el ejemplo de los hoteles con la variable Pcn, se estaría planteando que el hecho de tener piscina o no hace que los precios de los hoteles sean diferentes. La variable Est estaría marcando que los precios de los hoteles son diferentes para las distintas categorías hoteleras.
Estas diferencias puede analizarse de tres formas distintas:
- Observando el impacto de la diferencia sobre el término independiente.
- Observando el impacto de la diferencia sobre los coeficientes que acompañan a las variables explicativas.
- Observando el impacto de la diferencia en ambas situaciones, sobre el término independiente y sobre las variables explicativas.
1. Efecto de una dummy sobre el término independiente
Comenzaremos analizando el efecto de la variable Pcn sobre el término independiente. Para ello estimaremos la recta de regresión:

Este modelo tiene distinto término independiente para los hoteles con piscina y para los hoteles sin piscina.
- Si un hotel no tiene piscina, Pcn es igual a 0 por lo que la ecuación del modelo será:

- Si un hotel tiene piscina, Pcn es igual a 1 por lo que la ecuación del modelo será:
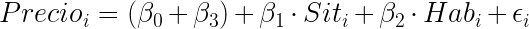
Vemos por tanto como al incluir una variable dummy estamos estimando en realidad dos ecuaciones, una para cada uno de los valores de la variable cualitativa.
En el caso anterior la única diferencia entre ellas estaría en el término independiente, que será diferente si el hotel tiene piscina o no. El parámetro que acompaña a la variable dummy marca por tanto, la diferencia entre el precio de los hoteles con piscina y el precio de los hoteles sin piscina.
La estimación del modelo anterior en Gretl es la siguiente:

Las ecuaciones para la predicción serán por tanto las siguientes:
- Para los hoteles que no tienen piscina:

- Para los hoteles que sí tienen piscina:
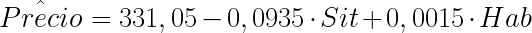
El contraste de significatividad individual se aplica a las variables cualitativas del mismo modo que a las variables cuantitativas. Se trata de un contraste relacionado con el parámetro estimado y no con la variable en sí, por lo que sigue teniendo sentido en el caso de variables cualitativas.
En el ejemplo anterior, con un p-valor de 0,0555 tendríamos que rechazar la hipótesis nula de no significatividad del parámetro a nivel de significatividad 0,1, pero no a nivel de significatividad 0,05. Si estuviésemos utilizando un nivel de significatividad de 0,1, y asumiésemos por tanto que la variable es significativa entenderíamos que hay diferencias en el precio entre los hoteles con piscina y sin piscina. En ese caso diríamos que los hoteles con piscina tiene un precio medio de la habitación 1,29 € más caro.
2. Efectos sobre los coeficientes que acompañan a las variables explicativas (esquema multiplicativo)
También debemos observar si las variables dummies afectan a la pendiente del resto de variables explicativas del modelo. Hablaremos en esta situación de analizar el esquema multiplicativo que presenta el modelo, ya que para analizar el efecto de las dummies sobre los betas de las variables explicativas, las incluiremos multiplicando a estas.
En nuestro ejemplo, si queremos estudiar un efecto diferente de la distancia a la playa sobre el precio de los hoteles según si tienen piscina o no debemos plantear el siguiente modelo:

donde la variable Sit·Pcn toma el valor de Sit cuando el hotel tiene piscina (Pcn=1) y vale cero cuando no la tiene (Pcn=0). Divide por tanto al modelo en los siguientes modelos:
- Si el hotel no tiene piscina:

- Si el hotel tiene piscina:

Para implementar este esquema multiplicativo en Eviews basta con indicar al software que incluya el producto de las variables que queramos, a la hora de estimar el modelo, del siguiente modo:

También se pueden crear variable nuevas con los productos mediante la opción Genr.
La estimación del modelo es la siguiente:

Las ecuaciones para la predicción serán ahora:
- Para los hoteles que no tienen piscina:

Para los hoteles que sí tienen piscina:
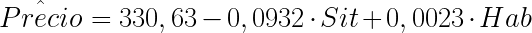
En este caso, a nivel de significación 0,05 la variable Sit_Pcn es significativa, por lo que existe un efecto diferencial sobre la situación del hotel, relacionado con el hecho de que tenga o no piscina.
Podemos decir que, por cada metro que un hotel se aleja de la playa, el precio medio de la habitación en temporada alta disminuye en 0,09398 €, para los hoteles que no tienen piscina. Este efecto es ligeramente inferior para los hoteles con piscina y la diferencia es de 0,000742. O dicho de otro modo, los hoteles con piscina disminuyen su precio en 0,094722 € por cada metro que se alejan de la playa. Hablamos por tanto de una diferencia de 0,74€ por kilómetro de distancia a la playa.
Podríamos estar también interesados en el efecto de la variable Pcn sobre el impacto del número de habitaciones en el precio. En este caso tendríamos que solicitar la inclusión de este producto (Hab*Pcn ) en el modelo en Eviews.
3.Efectos sobre todos los coeficientes del modelo
La última opción es incluir en un mismo modelo los efectos diferenciales de la variable dummy sobre todos los coeficientes y sobre el término independiente. En nuestro ejemplo, la especificación del modelo sería:

•De modo que si el hotel no tiene piscina, el modelo es en realidad:
- Y si tiene piscina:
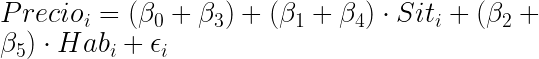
Y la estimación sería:

Al incluir tantas variables, es posible que tengamos un problema de multicolinealidad en el modelo, ya que se puede observar que se explica un 99,39% de la variabilidad de la variable dependiente y sin embargo el modelo solo presenta una variable significativa, de acuerdo con el contraste de significatividad individual.
Sería recomendable en este caso, estimar modelos que estimen el precio con distinto número de variables y compararlos mediante el R2 ajustado y los criterios de Akaike, Schwarz y Hannan-Quinn, para seleccionar el mejor.

En este caso todos los criterios indican que el mejor modelo para la predicción es el último, el que explica el precio a partir de la situación, incluyendo el efecto que tiene tener piscina sobre la situación. Se observa que para este modelo el 