Índice
¿Qué es la heterocedasticidad?
Se dice que un modelo de regresión lineal presenta problemas de heterocedasticidad si la varianza de su error no es constante para las diferentes observaciones, es decir homoscedastica.
La ausencia de homoscedasticidad en un modelo de regresión lineal supone el incumplimiento de una de sus hipótesis básicas, que asume que un modelo de regresión lineal tiene que tener un término error distribuido como una distribución normal, de media cero y varianza constante. El hecho de que la varianza no sea constante implica heterogéidad en la muestra, es decir, que los datos que la componen provienen de distribuciones de probabilidad con varianzas distintas.
La heteroscedasticidad se presenta con mayor frecuencia en datos de corte transversal, puesto que los diferente elementos que pueden componer una muestra (individuos, empresas, países…) no siempre presentan un comportamiento homogeneo. Las series temporales, por el contrario normalmente incluyen mayor homogeneidad en los datos, pero también podemos encontrar problemas de heteroscedasticidad en algunos casos.
Consecuencias de la Heterocedasticidad
El incumplimiento de la hipótesis de homocedasticidad en el modelo trae consigo las siguientes consecuencias en la estimación:
1.La matriz de varianzas-covarianzas no se calcula correctamente. Sabemos que esta matriz se obtiene mediante la expresión:

Como vemos, la expresión anterior utiliza la varianza del error como un valor único, de forma que si no es constante, la matriz de varianzas-covarianzas de los estimadores estará mal calculada. De este modo, en presencia de heterocedasticidad es necesario calcular la estimación de la matriz de varianzas-covarianzas de los estimadores de otro modo.
2.Perdida de eficiencia de los estimadores de mínimos cuadrados ordinarios. En presencia de heterocedasticidad las varianzas de los parámetros deben calcularse de otro modo y se incrementan, lo que hace que las estimaciones sean menos eficientes.
3.Al tener estimaciones para las varianzas de los estimadores más grandes y menos fiables, los contrastes de significatividad individual y global también serán menos fiables, puesto que utilizan estás varianzas en el cálculo de sus estadísticos de contraste.
Por lo demás los estimadores de mínimos cuadrados siguen siendo los mejores estimadores que pueden obtenerse. Siguen siendo insesgados, pero dejan de ser de varianza mínima.
Ejemplo de detección de la heterocedasticidad
Se pretende plantear un modelo que explique el gasto en ocio en un grupo de 50 individuos a partir de sus ingresos mensuales. Con los datos de la muestra se obtiene la siguiente estimación del modelo:

Podemos observar que la variable ingresos es significativa a la hora de explicar el gasto en ocio de los individuos y el modelo consigue explicar un 92,67% de la variabilidad del gasto en ocio.
Como el error no es una variable que podamos observar, para detectar la posible presencia de heterocedasticidad en un modelo tendremos que observar sus residuos, como muestra del error del modelo. Los contrastes para la detección de la heterocedasticidad constrastan la hipótesis nula de homocedasticidad en el modelo, frente a la alternativa de heterocedasticidad.
Métodos gráficos para la detección de heterocedasticidad
Comenzaremos analizando la posible existencia de heterocedasticidad en un modelo por medio de la observación de los gráficos de dispersión entre el valor absoluto del error, o su cuadrado y las variables explicativas. Estas representaciones gráficas nos darán una idea del comportamiento del error ante las variables explicativas. En los gráficos observaremos si la dispersión es constante o por el contrario varia a lo largo de las observaciones de la muestra.
Como habíamos comentado, observaremos el comportamiento de los residuos como muestra del error del modelo. Debemos obtener entonces gráficos del valor absoluto de los residuos o su cuadrado frente a las variables explicativas.
Comenzaremos obteniendo el gráfico del valor absoluto de los residuos frente a la variable ingresos. Para ello seguiremos los siguientes pasos:
1)Generar el valor absoluto de los residuos:
Genr: ABSresid=@abs(resid)
2)Una vez generada la nueva serie, la seleccionamos junto con RENTA y las abrimos como grupo.
3)Podemos observar el gráfico de dispersión entre ambas variables haciendo:
View -> Graph -> Basic Graph -> Scatter

El gráfico muestra como aumenta la dispersión del valor absoluto del error a medida que aumentan los ingresos del individuo. Esto es un claro indicio de presencia de heterocedasticidad en el modelo. Si el modelo fuese homocedastico, la dispersión del valor absoluto del error sería la misma para todos los valores de la variable ingresos.
Si hubiésemos obtenido el gráfico del cuadrado de los residuos frente a los ingresos encontraríamos un gráfico muy similar que nos llevaría a las mismas conclusiones.
Se podría pensar que teniendo contrastes de hipótesis que proporcionan una valoración más clara de la presencia de heterocedasticidad en un modelo, no tiene mucho sentido utilizar métodos gráficos. La ventaja de estos últimos radica en que nos permiten hacernos una idea del comportamiento de la heterocedasticidad, nos permiten observar por ejemplo, si es creciente, decreciente… En el caso de nuestro ejemplo, vemos claramente en el gráfico que a medida que aumentan los ingresos, aumenta la dispersión del error. Vemos por tanto que el gráfico presenta forma de embudo, mostrando un crecimiento lineal de la dispersión del error con el aumento de los ingresos.
En modelos con más de una variable explicativa debemos decidir frente a cuál de las variables explicativas realizamos el gráfico. Si no sabemos que variable puede previsiblemente generar heterocedasticidad en el modelo, lo recomendable es observar los gráficos de cada una de las variables explicativas frente al cuadrado de los residuos o su valor absoluto para encontrar si alguna está generando problemas. En este caso, también se puede observar el gráfico del cuadrado de los residuos (o el valor absoluto) frente a la variable estimada, por ser esta una combinación lineal de todas las variables explicativas. Así se podrá detectar la heterocedasticidad incluso si la genera una combinación lineal de variables.
Podemos obtener una serie con el valor estimado de la variable dependiente a través de la opción Forecast de la ventana del objeto ecuación.
Contrastes de hipótesis para la detección de la heterocedasticidad: el contraste de White
Además de los métodos gráficos existen numerosos contrastes de hipótesis para verificar la presencia de heterocedasticidad en el modelo. Analizaremos aquí el contraste de White.
Contraste de White
El contrate de White es el contraste más general para la detección de presencia de heteroscedasticidad en un modelo de regresión lineal múltiple. Esto es así porque no requiere una especificación concreta de cómo es la heterocesticidad bajo la hipótesis nula. Simplemente contrasta:
H0: σi2= σ2 para todo i.
H1: No se verifica H0.
Para efectuar este contraste se plantea un modelo auxiliar que pretende explicar el comportamiento del cuadrado de los residuos a partir de las variables explicativas, de sus cuadrados y de sus productos cruzados. Si el modelo es homocedástico, este modelo auxiliar no será significativo y no se podrá explicar el cuadrado de los residuos a partir de las variables explicativas, sus cuadrados y sus productos cruzados. Si por el contrario el modelo presenta un problema de heterocedasticidad, este modelo auxiliar sí será significativo.
Cuando el modelo es homocedástico, se cumple que 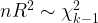
En Eviews este contraste se encuentra en las opciones del objeto ecuación:
View ->Residual diagnostic -> Heteroskedasticity test
Dentro de esta opción el software ofrece distintos contrastes para la detección de heterocedasticidad, elegiremos en este caso el de White. Al seleccionarlo podemos elegir entre incluir términos cruzados o no. Es bueno incluir los términos cruzados para tener en cuenta todas las posibilidades. No obstante, si nuestro modelo incluye muchas variables y no tiene muchos datos no será posible estimar un modelo auxiliar con todos los cuadrados y cruces de las variables explicativas. En este caso será mejor no seleccionarlos para poder realizar el contraste.

Observamos que la salida del contraste incluye el modelo auxiliar obtenido en la parte inferior, y en la parte superior tres formas distintas de verificar si el modelo auxiliar planteado es significativo o no. Todas están contrastando la hipótesis nula de homocedasticidad en el modelo, frente a la alternativa de heterocedasticidad. El contraste de white original es el que contrasta la hipótesis nula en base a 
Como comentábamos, el contraste de White tiene la ventaja de ser muy flexible ya que que puede hacer sin especificar la forma de la heteroscedasticidad. Pero esta ventaja es también una desventaja si pensamos que, al detectar la heteroscedasticidad no proporciona información alguna sobre la forma que tiene, para con esta información tratar de resolver el problema.