Supongamos que una empresa está interesada en encontrar los factores que afectan al gasto anual en reparaciones de maquinaria parar la producción (GR). Esta será por tanto nuestra variable dependiente (Y). Inicialmente se plantea como variables explicativas la antigüedad de la maquinaria medida en años (ANT), el gasto anual en revisiones (REV) y las horas de funcionamiento anuales (FUN). Se dispone para el estudio de una muestra de datos que incluye 50 maquinas en el archivo “gasto_maquinaria.gdt”.
Índice
- Hipótesis previas
- Análisis descriptivo de las variables del modelo
- Análisis de relaciones con la variable dependiente
- Estimación del modelo
- Interpretación de los parámetros estimados
- Contraste de normalidad
- Error estándar
- Contraste de significatividad individual
- Coeficiente de determinación
- Coeficiente de determinación corregido
- Contraste de significatividad global
- Criterios de información de Akaike y Schwarz
- Algunas opciones de la ventana del modelo en Gretl
- Vídeos
Hipótesis previas
Antes de nada debemos plantearnos las relaciones que esperamos encontrar entre las variables explicativas y la variable dependiente. Estas serán nuestras hipótesis previas.
En nuestro ejemplo se espera que la relación entre el gasto anual en reparaciones y la antigüedad sea positiva, es decir, que cuantos más años tiene una máquina, mayor será el gasto en reparaciones. Con respecto al gasto anual en revisiones, se espera encontrar una relación negativa con el gasto en reparaciones, de forma que cuanto mayor sea el gasto revisiones, menor sea el gasto en reparaciones. Finalmente se espera que las horas de funcionamiento tengan una relación positiva con el gasto en reparaciones, ya que cuanto mayor sea el tiempo de funcionamiento de una maquina, previsiblemente mayor será el número de reparaciones que precise. En resumen, las relaciones que esperamos encontrar son:
| Antigüedad | + |
| Gasto en revisiones | – |
| Tiempo de funcionamiento | + |
Análisis descriptivo de las variables del modelo
Todo estudio estadístico debe comenzar con un análisis descriptivo de las variables que intervienen, para conocerlas mejor y centrar adecuadamente el análisis. Es importante explicar bien con que variables estamos trabajando y como se miden. Podemos obtener una tabla con los principales estadísticos descriptivos de las variables a través del menú:
Ver –> estadísticos principales
Y el resultado será:

Análisis de relaciones con la variable dependiente
Una vez planteado el modelo y las hipótesis previas, podemos analizar las relaciones existentes entre las variables explicativas y la variable explicada, para confirmar si existe entre ellas una relación lineal. Para obtener los gráficos de dispersión en Gretl usaremos la secuencia:
Ver -> Gráficos múltiples -> Gráficos X Y (Scatter)
Que nos llevará al siguiente cuadro de diálogo:

Y el resultado será:

Las variables antigüedad y gasto en revisiones tienen una clara relación lineal con la variable dependiente. Como esperábamos, esta relación es positiva en el caso de la variable antigüedad y negativa en el caso del gasto en revisiones. Con la variable horas de funcionamiento anuales, el gasto en reparaciones presenta una relación positiva pero no tan claramente lineal con el caso de las anteriores.
En este caso los gráficos muestran relaciones lineales bastante claras, no obstante se deben corroborar también mediante la matriz de correlaciones. Para ello usaremos la secuencia:
Ver -> matriz de correlación
Si colocamos la variable dependiente la última de la lista aparecerá al final de matriz y tendremos toda la información que nos interesa junta.

La matriz de correlaciones muestra el coeficiente de correlación entre cada par de variables. Nos interesa que las variables independientes estén muy relacionadas con la variable dependiente, para que puedan explicar adecuadamente su variabilidad.
Comprobamos que la relación es fuerte y lineal entre el gasto en reparaciones y la antigüedad y el gasto en reparaciones y el gasto en revisiones. Positiva en el caso de la primera y negativa con la última. La relación entre el gasto en reparaciones y las horas de funcionamiento de la maquinaria no es tan fuerte, es moderada y positiva.
Nos interesará también que las variables independientes no presenten fuertes correlaciones entre sí. Si así fuera tendríamos un problema de multicolinealidad en el modelo. En este caso observando la matriz de correlaciones vemos hay una fuerte correlación entre el gasto en revisiones y la antigüedad, lo podría significar un problema de multicolinealidad. Obviaremos este problema que estudiaremos más adelante y continuaremos con nuestro análisis.
Estimación del modelo
El modelo que nos planteamos estimar es el siguiente:

Para estimarlo usaremos la siguiente secuencia de Gretl:
Modelo -> Mínimos cuadrados ordinarios…

Debemos seleccionar la variable dependiente en el recuadro superior y las variables independientes en el inferior. “const” se refiere al término constante del modelo.
El resultado de la estimación es el siguiente:

En la parte superior el software nos informa de las observaciones empleadas en la estimación del modelo y el nombre de la variable dependiente.
A continuación aparece una tabla con los resultados de la estimación. La tabla incluye por columnas: los nombres de las variables, las estimaciones de cada uno de los coeficientes, las desviaciones típicas de los estimadores y el contraste de significatividad individual con su p-valor asociado.
La zona inferior incluye un conjunto de estadísticos de bondad de ajuste, que nos permitirán realizar una evaluación parcial de la estimación realizada.
La columna coeficiente incluye el valor de los estimadores de los parámetros asociados a cada una de las variables explicativas. Estos valores se han obtenido mediante una estimación por el método de mínimos cuadrados ordinarios, a partir de la expresión matricial:

Sabemos por el teorema de Gauss-Markov que, si se cumplen las hipótesis clásicas del modelo de regresión múltiple, éstos estimadores son lineales, insesgados y óptimos (ELIO). Estos estimadores miden la magnitud de influencia de cada variable sobre la variable dependiente, entendiendo que las demás permanecen constantes.
La ecuación estimada para este modelo es por tanto:

Con esta ecuación podríamos predecir el gasto anual en reparaciones que tendrá una máquina, conociendo su antigüedad, su gasto en revisiones y sus horas de funcionamiento anual, asumiendo que el modelo cumple con todas las hipótesis básicas.
Interpretación de los parámetros estimados
Como ya adelantábamos, los parámetros del modelo miden la magnitud de la influencia de cada variable explicativa, sobre la variable dependiente. Tal y como está especificado nuestro modelo los coeficientes están midiendo la variación que experimenta la variable endógena ante un cambio de una unidad en la variable explicativa correspondiente, suponiendo que el resto de variables permanecen constantes.
En nuestro ejemplo diremos que:
- Cuando se aumenta la antigüedad de la máquina en una unidad, el gasto en reparaciones aumenta en 64,09 unidades, siempre que el resto de variables permanezcan constantes.
- Si el gasto en revisiones aumenta en una unidad, el gasto en reparaciones disminuye en 7,57 unidades, siempre que el resto de variables permanezcan constantes.
- Y finalmente, si las horas de funcionamiento anual aumentan en una unidad, el gasto en reparaciones disminuye en 0,0019 unidades, siempre que el resto de variables permanezcan constantes.
Por supuesto, esta interpretación esta siempre supeditada a la validez del modelo, que aún no hemos analizado.
Es frecuente que los modelo requieran incluir transformaciones logarítmicas en algunas variables para resolver algunos problemas que pueden surgir. Si utilizamos este tipo de transformaciones, la interpretación de los parámetros es diferente y se resume en la siguiente tabla:
| Modelo | Variable dependiente | Variable independiente | Interpretación del parámetro |
| Nivel-nivel | y | x |  |
| Nivel-log | y | Log(x) |  |
| Log-nivel | Log(y) | x |  |
| Log-log | Log(y) | Log(x) |  |
(Wooldridge, J. Introducción a la econometría: un enfoque moderno. 2006. Ed. Thomson. Pg. 49)
Contraste de normalidad
Antes de comenzar a analizar los contrastes de hipótesis asociados al modelo de regresión lineal múltiple es importante comprobar si se cumple la hipótesis de normalidad del error (H7). Recordemos que la hipótesis 7 decía: “El término error es un término completamente aleatorio que sigue una distribución normal, de esperanza 0 (E[εi]=0).”
Los contrastes de hipótesis asociados al modelo de regresión múltiple son todos contrastes paramétricos, por lo que no serán aplicables si no se cumple esta hipótesis de normalidad del error. Para comprobar la normalidad del error se puede utilizar cualquiera de los contrastes de normalidad que incorpora Gretl sobre la serie de los residuos del modelo.
Para realizar el contraste de normalidad en Gretl podemos guardar los residuos a través del menú del modelo:
Guardar -> Residuos
Y después aplicar a esta serie cualquiera de los contrastes de normalidad (desde el menú general).
Otra opción es realizar el contraste de normalidad para los residuos directamente a través del menú del modelo:
Contrastes -> Normalidad de los residuos
En este caso nos dará la distribución de frecuencias y el contraste de Doornik-Hansen.


Comprobamos mediante el contraste de Doornik-Hansen que los residuos provienen de una distribución normal, por lo que podemos considerar que el error en normal y se cumple la hipótesis 7.
El cumplimiento de esta hipótesis nos permite seguir adelante con el estudio. Si no se cumpliese la hipótesis de normalidad, los contrastes que utilizaremos a partir de ahora para comprobar el grado de validez del modelo no serían válidos, ya que todos están basados en esta hipótesis. Tendríamos por tanto que reespecificar el modelo, porque no sería válido. Es importante, por tanto realizar este contraste antes que el resto, para asegurar su validez.
Error estándar
Volviendo a la información que proporciona Gretl sobre la estimación del modelo, junto a la columna de coeficientes tenemos la columna Desv. Típica que muestra la varianza de los estimadores de los parámetros del modelo o error estándar de estimación. La desviación típica de los estimadores, mide la precisión con la que dichos estimadores estiman los parámetros del modelo. Es, por tanto un indicador del grado de confianza que podemos tener en la estimación. Sabemos por el teorema de Gauss- Markov que, siempre que se cumplan las hipótesis básicas del modelo, los estimadores de mínimos cuadrados ordinarios son eficientes, es decir, que tienen la menor varianza (y en consecuencia desviación típica) que pueden tener.
Contraste de significatividad individual
Las dos últimas columnas contienen el estadístico t y su p-valor asociado. Ambas hacen referencia al contraste de significatividad individual. Este contraste contrasta la hipótesis nula de que la variable considerada no es individualmente significativa para explicar el comportamiento de la variable dependiente, es decir:

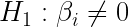
El estadístico de contraste de este test es:

Sabemos que bajo la hipótesis nula, el estadístico t sigue una distribución t de student con n-k-1 grados de libertad. La región crítica será por tanto: |t|≥tn-k-1,α/2.
La forma más sencilla de trabajar con el contraste de significatividad individual es tomar la decisión sobre la hipótesis nula en base al p-valor. Recordemos que el p-valor nos indica la probabilidad de cometer el error de rechazar la hipótesis nula siendo cierta (error de tipo I).
En el modelo planteado no tenemos evidencias suficientes para rechazar la hipótesis nula de no significatividad de las variables, únicamente en el caso de las horas de funcionamiento anuales de la máquina. Para el resto de variables, la hipótesis nula de no significatividad individual de la variable se debe rechazar, por lo que aceptaremos que sí son significativas.
En la parte inferior, lo primero que aparece es la media aritmética de la variable dependiente, que como sabemos coincidirá con la de su estimación. Al lado está la desviación típica de la variable dependiente.
A continuación tenemos la suma de cuadrados de los residuos (SCE) o variabilidad no explicada por el modelo (VNE). Se obtiene mediante:

El dato D.T. de la regresión es la estimación de la desviación típica del error, de modo que su cuadrado es la varianza del error. Se obtiene mediante la siguiente expresión:

Coeficiente de determinación
En la tabla inferior aparece el coeficiente de determinación (R-cuadrado (R2)), que como ya sabemos es una medida para valorar la capacidad explicativa de la regresión.
Se define como el cociente entre la variación explicada o suma explicada de cuadrados (SEC) y la variación total:

Nos informa por tanto del porcentaje de variación de la variable dependiente que conseguimos explicar con el modelo.
En nuestro ejemplo vemos que la capacidad explicativa de las variables es elevada, pues explican el 96,70% de la variabilidad de la variable endógena.
Coeficiente de determinación corregido
El coeficiente de determinación corregido, R-cuadrado corregido (

Este coeficiente permite comparar la capacidad explicativa de modelos referidos a una misma muestra de la misma variable dependiente con distinto número de variables independientes. En nuestro caso obtenemos un valor de 0,9649. Si lo comparamos con el valor que obtenemos al estimar un modelo con las mismas variables explicativas menos las horas de funcionamiento (0,9656), podemos concluir que este último modelo es mejor que el anterior por ser el R cuadrado ajustado mayor. Si comparásemos directamente el coeficiente de determinación observaríamos que este siempre sube al incluir nuevas variables, aunque no sean significativas.
Contraste de significatividad global
El contraste de significatividad global (F(3,46)), permite contrastar:


Contrasta si todos los parámetros asociados a cada una de las variables explicativas del modelo son iguales a cero. Es por tanto, una forma de comprobar si el modelo es válido o debemos especificarlo de nuevo. La alternativa indica que al menos uno de los parámetros es significativo o distinto de cero.
El estadístico de contraste es:

Bajo la hipótesis nula, el estadístico F sigue una distribución F-Snedecor (n-1;n-k-1), de modo que la región crítica será: F>F-Snedecor (n-1;n-k);α
El contraste de significatividad global se puede entender como la forma de comprobar si el coeficiente de determinación del modelo es suficientemente grande como para considerar que el modelo tiene una capacidad explicativa adecuada. En nuestro caso, con un p-valor de 4.34e-34 se debe rechazar la hipótesis nula, por lo que se acepta que el modelo es significativo.
Log verosimilitud nos da el valor máximo de la función de verosimilitud. Este es el valor de la función de verosimilitud para los parámetros, ya que estos son los más verosímiles o los que maximizan la probabilidad de la muestra.
Criterios de información de Akaike y Schwarz
Los criterios de información de Akaike y Schwarz proporcionan un método para la elección del mejor modelo a partir de una misma muestra. Ambos son medidas de la perdida de información que tenemos al modelizar la variable con el modelo planteado. Se calculan a partir de las siguientes expresiones:
AIC = -2*(L/N)+2*((k+1)/N)
BIC = -2*(L/N) + (k+1)*Ln(N)/N
Siendo L el valor máximo de la función de verosimilitud, k el número de variables explicativas del modelo y N el tamaño muestral.
Algunas opciones de la ventana del modelo en Gretl
La ventana del modelo en Gretl tiene su propio menú que incorpora acciones que podemos realizar con el modelo. En el apartado de contrastes se incluyen importantes contrastes sobre el modelo que serán de interés, como el contraste de normalidad del error que ya hemos utilizado.
A través del menú guardar, podemos guardar como escalares los valores obtenidos en la estimación. Y el menú de gráficos obtiene interesantes gráficos sobre los residuos y sobre las predicciones.
Gráfico de la variable observada frente a la estimada

Predicciones
Podemos obtener las predicciones del modelo mediante el menú:
Análisis -> Predicciones


Intervalos de confianza para los coeficientes
Además de la predicción puntual, podemos obtener intervalos de confianza para los coeficientes a través del menú:
Análisis -> Intervalos de confianza para los coeficientes

Matriz de varianzas-covarianzas de los estimadores
La matriz de varianzas-covarianzas de los estimadores se obtiene mediante:
Análisis -> Matriz de covarianzas de los coeficientes
