Índice
Introducción
Definición.- Población
En estadística se denomina población al conjunto de todos los individuos que son objeto de estudio y sobre los que se desea obtener información.
Toda población se caracterizará probabilísticamente mediante variables aleatorias, cada una de las cuales tendrá una distribución de probabilidad asociada.
Llamaremos N al tamaño de la población y buscaremos tener información para los N individuos incluidos en la población.
En la mayoría de los casos no será posible acceder a toda esa información y tendremos que conformarnos con extraer una muestra.
Definición.- Muestra
Una muestra es el conjunto de individuos a cuya información realmente tendremos acceso dentro de la población.
Toda muestra debe ser un buen reflejo de la población de la que proviene. Si es así diremos que la muestra es representativa.
Denominaremos “n” al tamaño muestral, y a partir de la información de los “n” individuos de la muestra, tendremos que inferir el comportamiento de la población de “N” individuos.
Definición.- Elemento
Un elemento es cada uno de los componentes de la población en estudio. Los elementos a menudo se denominan individuos, aunque las poblaciones pueden tener elementos de distintas naturalezas (personas, empresas, países, productos…).
Definición.- Variable
En estadística se denomina variable a cualquier característica del elemento o ítem en estudio.
Las variables estadísticas no son siempre numéricas y pueden ser también de carácter cualitativo. A las variables cualitativas las denominaremos atributos o simplemente variables cualitativas.
Definición.- Dato
Un dato es el valor concreto que toma una variable para un individuo de la muestra. Dependiendo de la naturaleza de la variable que consideremos los datos pueden ser numéricos o no.
Dependiendo se su naturaleza el conjunto de datos puede ser:
- Datos históricos o series temporales.
- Datos de corte transversal.
- Datos de panel.
Los datos históricos o series temporales nos ofrecen información para una variable y para un mismo elemento o ítem a lo largo del tiempo.
Los datos de corte transversal nos ofrecen información sobre una variable para diferentes elementos.
Los datos de panel nos ofrecen información sobre na variable para diferentes elementos a lo largo del tiempo.
Inferencia
Definición.- Inferencia
La inferencia es el conjunto de técnicas, métodos y procedimientos que permiten obtener conclusiones sobre el comportamiento estadístico de una población, a partir de la información contenida en una muestra.
Definición.- Estadístico
Un estadístico es cualquier función de elementos muestrales, que no contenga parámetros desconocidos.
Los estadísticos se calculan con el objetivo de inferir características de la población a partir de las características de la muestra.
Definición.- Estimador
Un estimador es cualquier función de elementos muestrales, es decir, cualquier estadístico, que se utilice para realizar una estimación.
Diremos que estamos estimando un parámetro poblacional desconocido, cuanto tratemos de darle un valor adecuado en base a la información muestral que tengamos. Este tipo de estimación se denomina estimación puntual, ya que pretende dar un valor concreto al parámetro.
Existen dos tipos de estimación:
- La estimación puntual, que consiste en encontrar un valor concreto que estime el verdadero valor del parámetro.
- La estimación por intervalos, que consiste en encontrar un intervalo de confianza en el que se tenga una cierta certeza de que encontraremos el verdadero valor del parámetro.
Definición.- Intervalo de confianza
En el contexto de la estimación, un intervalo de confianza es un rango de valor es calculado a partir de elementos muestrales, en el que se encuentra el verdadero valor del parámetro, con una certeza determinada.
Hablamos en términos de certeza o fiabilidad y no de probabilidad porque el valor del parámetro es un valor fijo pero desconocido y no una variable aleatoria.
Propiedades de los estimadores
Los estimadores pueden tener las siguientes propiedades:
- Insesgadez
- Eficiencia
- Consistencia
- Suficiencia
- Invariabilidad
- Robustez
Insesgadez
Se dice que un estimador es insesgado cuando la esperanza matemática de su distribución en el muestreo coincide con el valor del parámetro.
Generalmente la esperanza matemática de un estimador se puede expresar como:
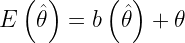
Siendo 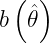
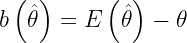
- Si el sesgo es positivo (
- Si el sesgo es negativo (
- Si el sesgo es cero (
Si el un estimador es insesgado diremos que

Diremos que un estimador es asintóticamente insesgado si,

Eficiencia
Se dice que un estimador es eficiente u óptimo cuando su varianza es mínima.
Se puede calcular la varianza mínima de un estimador calculando la denominada Cota de Cramér-Rao, a partir de la siguiente expresión:
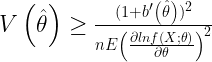
Siendo f(X; θ) la función de probabilidad que depende del parámetro desconocido θ, X la muestra aleatoria y n el tamaño muestral.
Un estimador es eficiente u óptimo cuando su varianza coincide con la Cota de Cramér-Rao.
Consistencia
Diremos que un estimador es consistente cuando, si el tamaño muestral “n” tiende a infinito el estimador es insesgado y de varianza cero, es decir
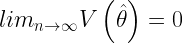

La última condición equivale a decir que el estimador es asintóticamente insesgado o
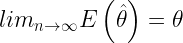
Suficiencia
Un estimador es suficiente cuando incluye toda la información relevante de la muestra, de forma que ningún otro estimador puede considerar información adicional.
Invariabilidad
Un estimador es invariable cuando si transformamos el parámetro a estimar mediante una función g(θ), dicha función puede ser estimada por la función del estimador g(θ^).
Tendríamos un ejemplo en la relación entre la varianza y la desviación típica. Si suponemos que la varianza muestral es un buen estimador de la varianza poblacional, la desviación típica muestral debería serlo de la desviación típica poblacional.
Robustez
Un estimador es robusto cuando si se vulnera alguno de los supuestos en los que se basa el proceso de estimación, la estimación no cambia significativamente y sigue ofreciendo resultados fiables.
Contraste de hipótesis
Definición.- Contraste de hipótesis
El contraste de hipótesis es una herramienta que, como su propio nombre indica, nos permite contrastar una cierta hipótesis relacionada con algún parámetro poblacional o con la propia estructura de datos de la población.
Definición.- Hipótesis nula
La hipótesis nula es el enunciado para el que se plantea para corroborar o descartar su validez por medio del contraste de hipótesis. Esta hipótesis debe estar referida a información poblacional que comprobaremos mediante la información muestral.
La hipótesis nula se denota por H0.
Definición.- Hipótesis alternativa
La hipótesis alternativa es el resultado esperado si finalmente concluimos que no se cumple la hipótesis nula. La denotaremos por H1.
Definición.- Estadístico de contraste
El estadístico de contraste será la función de elementos muestrales o estadístico que utilicemos para la realización del contraste.
Definición.- Región crítica
Llamaremos Región Crítica al conjunto de valores que puede tomar nuestro estadístico de contraste y que hacen constituyen una evidencia suficiente para afirmar que la hipótesis nula es falsa.
Definición.- Región de aceptación
Llamaremos Región de Aceptación al conjunto de valores que puede tomar nuestro estadístico de contraste que no constituyen una evidencia suficiente para rechazar la hipótesis nula.

Al realizar un contraste de hipótesis podemos tener las siguientes situaciones:

- La probabilidad de cometer este error de tipo II se denota por β y nos ayuda a calcular lo que denominamos potencia del contraste. La potencia del contraste es la probabilidad de rechazar la hipótesis nula cuando es realmente falsa y se calcula como 1 – β. También la podemos expresar como la probabilidad de aceptar la hipótesis alternativa cuando es cierta.
- La probabilidad de cometer error de tipo I se denomina nivel de significación del contraste y se designa por α. El nivel de significación es fijado por el investigador y habitualmente se trata de minimizar lo máximo posible. Son valores de uso habitual para el nivel de significación 0,1, 0,05 o 0,01.
p-valor
El p-valor es el nivel de significación más pequeño con el que se debe rechazar la hipótesis nula, teniendo en cuenta la información de la muestra observada.
Otras formas de expresarlo:
- Probabilidad de que el valor observado del estadístico de contraste esté en la región crítica, cuando la hipótesis nula es cierta.
- Probabilidad de que el estadístico de contraste observado nos indique que debemos rechazar la hipótesis nula, cuando es cierta.
Se calcula como:
P( El valor observado del estadístico esté dentro de la región crítica/H0)
El p-valor proporciona una regla de decisión tan válida como la región crítica y más sencilla de manejar, ya que la mayoría de los software estadísticos incluyen su cálculo en los contrastes de hipótesis que incorporan.
La regla de decisión es que, una vez fijado el nivel de significación, si este es mayor que el p-valor obtenido rechazaremos la hipótesis nula y de lo contrario diremos que no tenemos evidencias suficientes para rechazarla, es decir:

El nivel de significación no debe determinarlo el p-valor obtenido , debe decidirse antes de realizar el muestreo y en ningún caso dependerá el p-valor o del valor del estadístico.
El estudio econométrico
Concepto de econometría
<<La econometría se puede definir como la ciencia social en la que se aplican las herramientas de la teoría económica, las matemáticas y la inferencia estadística al análisis de los fenómenos económicos.>>
(Arthur S. Goldberg, Econometric Theory, Wiley, Nueva York, 1964, p1)
<<La econometría se basa en el desarrollo de métodos estadísticos destinados a estimar las relaciones económicas, contrastar teorías económicas y evaluar y poner en práctica políticas gubernamentales y de negocio.
La aplicación más común de la econometría es la predicción de variables macroeconómicas tan importantes como los tipos de interés, las tasas de inflación o el producto interior bruto.>>
(Jeffrey M. Wooldridridge, Introducción a la econometría. Un enfoque moderno, 2ª edición, Thomson, 2006, p2)
Ejemplos
Una empresa podría estar interesada en analizar los factores que afectan a las ventas de uno de sus productos. A priori podría plantearse que dependerán del precio del producto y de la inversión que se realice en marketing y publicidad.
Se podría estar interesado en estudiar la renta de un individuo en función de su nivel de estudios y de su edad.
Un gobierno podría estar interesado en estudiar los factores que afectan a su tasa de paro. A priori se podría plantear un modelo que trate de explicar la tasa de paro en función de la población activa y de la productividad.
Las variables del modelo
Variable Dependiente
Es la variable cuya variabilidad se pretende explicar a partir de los valores del resto de variables. Se le llama también variable explicada, endógena o simplemente y.
Variables Independientes
Son las variables a partir de las cuales se pretende explicar la variabilidad de la variable dependiente. Se les llama también variables explicativas, exógenas o simplemente Xi.
En el modelo econométrico se supone que la variable dependiente se ve afectada por el comportamiento de las variables independientes y no al revés.
Fases de un estudio econométrico

- Definición y especificación del problema que queremos resolver.
- Recopilación de datos. ( Necesitamos información cuantitativa, Tipos de datos: Series temporales; Datos de sección cruzada; Datos de panel).
- Fuentes de datos: Calidad y cantidad
- Selección del modelo matemático a utilizar (regresión lineal, no lineal, simple, múltiple, logística…)
- Especificación del modelo estadístico o econométrico concreto, incluyendo las variables en la estructura del modelo matemático del modo adecuado.
- Estimación de los parámetros del modelo econométrico elegido.
- Contrastación y diagnosis. Se trata de un análisis de la validez del modelo. Incluye contrastes de hipótesis para analizar el cumplimiento de las hipótesis básicas y validez de la especificación inicial.Si tras esta fase se concluye que el modelo presenta problemas hay que volver al punto 4 reespecificarlo.Si la contrastación y diagnosis concluye que el modelo es correcto pasaremos a la siguiente fase.
- Aplicación del modelo para hacer predicciones o previsiones.
- Toma de decisiones en base a la información obtenida.